AI
AI用の機械学習(学習データ、適用データ、テストデータ)データ整備を複数人で作成しているが、品質にばらつきがあり、AIで思うような結果が得られない。
顧客
- 業種:ITベンダー
- 部署:情報システム部
- 利用シーン:機械学習、データ前処理
背景
AI(人工知能)やビッグデータのビジネス活用が進むなかで、長年社内に蓄積され続けてきた未活用のビッグデータ(いわゆるダークデータ)の活用が経営課題としてあがっていました。社内での一つの事例として、ある機器のログを分析して、その機器の故障の傾向やメンテナンス時期の判断を行うことになりましたが、全世界を対象とした非常に巨大な規模のデータであったため、データを処理するシステムもスキルも不足しており、行き詰っていました。ひとまず限定したデータでの処理を試すことにしましたが、少数のデータでは望んだような結果が得られず、データ数を増やそうにも作業担当者によって、データ前処理をとっても品質のばらつきが大きく、上手くいきませんでした。そのため、誰もが簡単にビッグデータの前処理を高速に行えるツールやサービスを検討していました。
課題と効果
-
データサイズが大きいため、データ内容の確認に時間がかかり、データ整備に着手できない。
→
データ整備サービスは、最大20億行のデータを扱えるため、データ確認を行った後データ整備を行うことができました。
-
データが膨大なため、複数人で作業を行っているが、品質にばらつきがある。
→
データ整備サービスは、全データに対して同じ処理を行うため、担当者による品質のばらつきがなくなりました。
-
システム投資や専門の担当者育成に時間をかけられない。
→
現場の技術者が求める情報を仕様として伝えることで、データ整備/加工後のCSVファイルを作成できました。
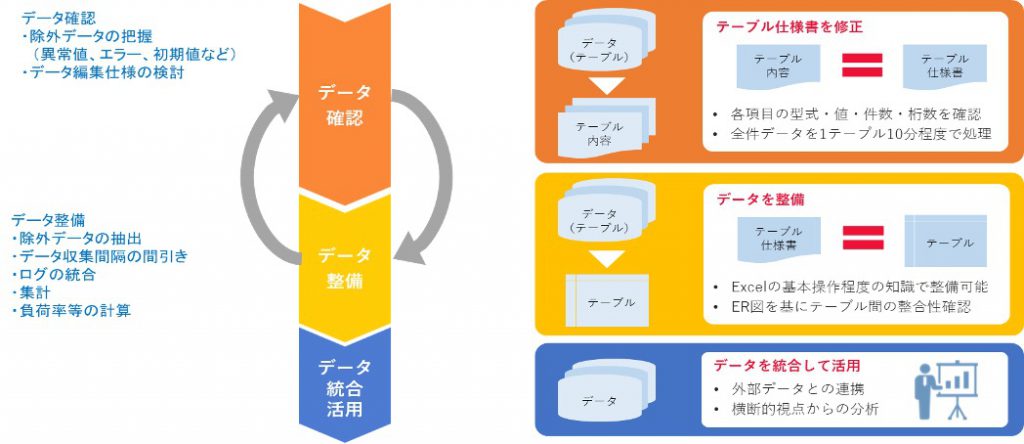
利用イメージ
まず、データ確認で対象ログデータの内容をレポートにして、実際にどのようなデータが存在するのか、異常値やエラー、信号が未入力で入力された初期値など、除外すべきデータを確認しました。その後、機器の設定やバージョンごとの差異を吸収する処理やデータの収集間隔をそろえるなど、全データを統合するために形式をそろえるデータ整備を行いました。
現場の技術者が統合したデータ内容を確認することで、実際のデータ加工、分析の具体的な指示が出るようになり、統合したデータに対する抽出や集計、計算処理を再びデータ整備サービスで実施することで、最終レポートの元データを作成することができました。この検証により、具体的な手順を整理できたため、この事例は定型処理化され定期レポートとして活用されています。この事例と同様に新たな処理や取り組みの際に、本番データを使って処理をするとどのような結果になるのかを低コストで検証する手段として、当社のデータ整備サービスを利用いただいております。