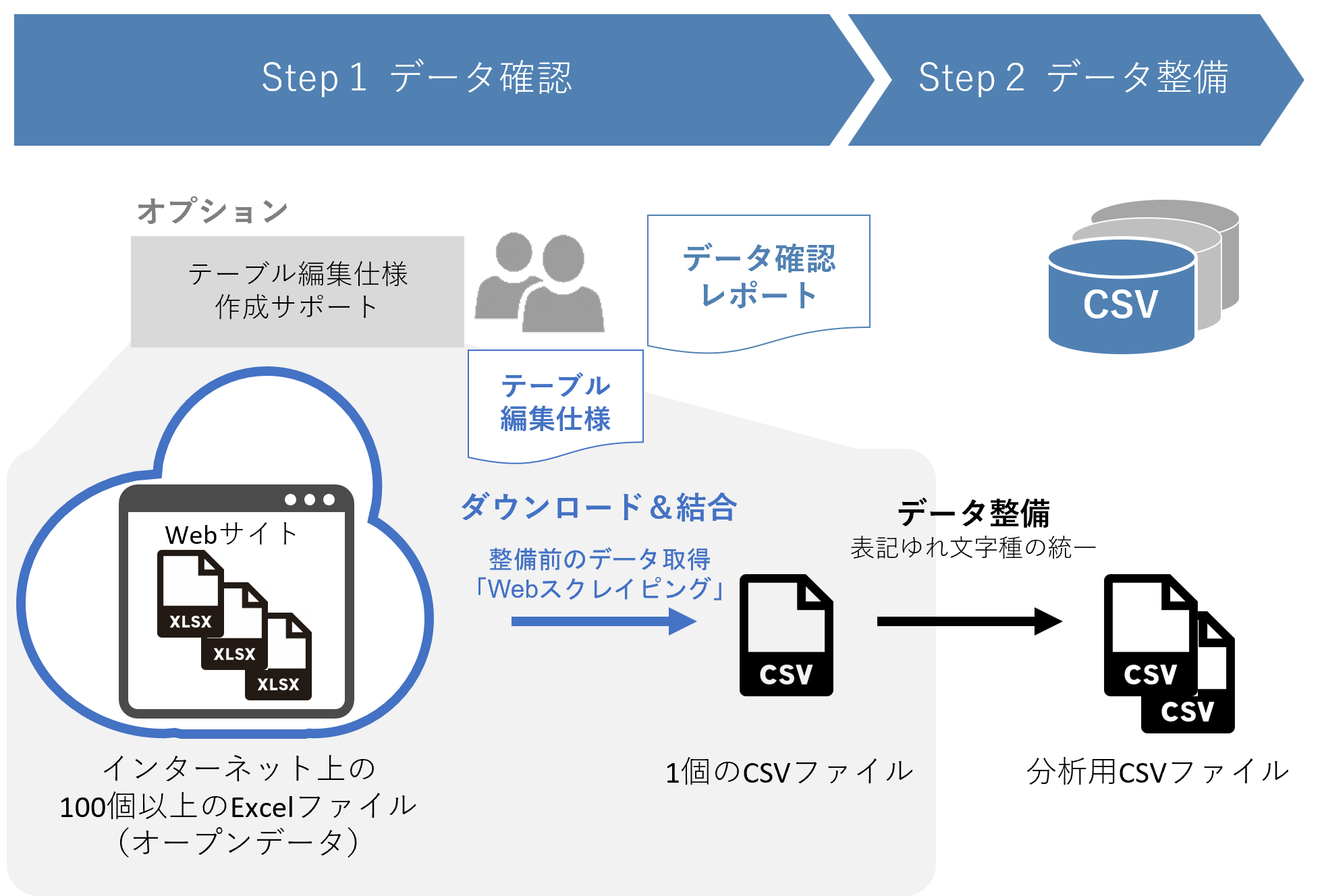
オープンデータのデータ整備
政府が提供するオープンデータをテキストマイニングツールで分析しようとしましたが、単語の正規化(表記ゆれの吸収、文字種の統一)や、大量のファイルを手作業でダウンロードしてから一つのデータに結合しようとすると、想像以上の手間がかかることがわかりました。簡単に行う方法を探していたときに当社のデータ整備サービスが役立ちました。
顧客
- 業種:研究機関
- 部署:
- 利用シーン:オープンデータ活用、テキストマイニング
背景
厚生労働省のオープンデータ(100以上のExcelファイル)をWebサイトからダウンロードして一つのファイルに結合が必要でした。次に結合したデータをテキストマイニングツールで分析しようとしましたが、記入者により単位の表記がバラバラ(「kg」と「キログラム」、「㎥」と「m3」)だったり、英数字に全角半角が混在していたり、表記ゆれの吸収や文字種の統一(単位、句読点、カタカナ、英数字、記号)といったデータ整備(データ前処理)が必要であることがわかりました。手作業では非効率なため、簡単にできるツールやサービスを調査していたところ、データ整備サービスを知り、テーブル編集仕様作成ポートで相談しながら分析用データの前処理を実現しました。
課題と効果
-
Webサイトから手作業でデータダウンロードを行うのが大変。
→
テーブル編集仕様作成サポートで相談することで、ファイルダウンロードや自動化スクリプト作成を支援してもらえました。
-
オープンデータを取得しても、分析や機械学習を行うためのデータ加工処理に時間がかかっている。
→
データ整備サービスを利用してデータの前処理を委託することで、本来の業務(データ分析)に集中することができました。
-
データに明らかな誤りが含まれている。
→
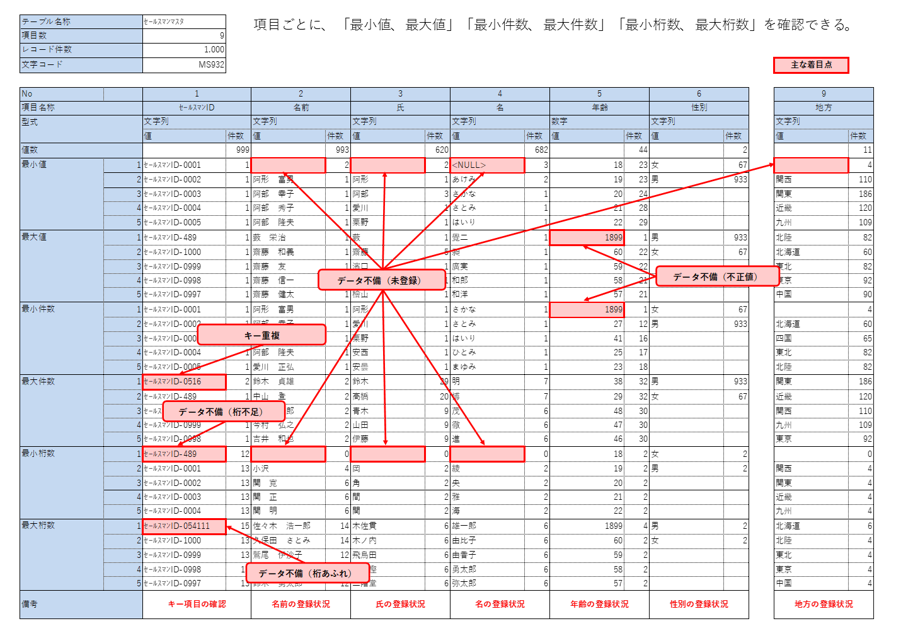
データ確認レポート(項目ごとに「最小値、最大値」「最小件数、最大件数」「最小桁数、最大桁数」を確認できる)を見ることで、コードに含まれる異常値を把握できました。データを確認して、明らかな入力ミスを正しいコードに置換したり、異常値を「Null」にするといった修正を行い、後の分析が行いやすくなりました。
データ確認レポート
利用イメージ
厚生労働省が公開しているオープンデータの取得と、分析のためのデータ前処理をデータ整備サービスとテーブル編集仕様作成サポートを利用して行いました。
分析対象のオープンデータは、API(アプリケーション・プログラミング・インターフェース)が提供されておらず、WebサイトからExcelデータをダウンロードする形式で過去20年分以上公開されています。年別データは20以上、月別データであれば100以上のファイルに分かれており、今後も様々なオープンデータを扱って分析処理することを考えると、手軽にデータを取得して整備するツールやサービスを必要としていました。
データ整備サービスのオプションのテーブル編集仕様作成サポートを利用することで、Webサイトからのデータ取得(ダウンロード)についてもサポートがあり、データ内容を確認したうえで、分析ツールで扱うためにどのように修正すればよいかを相談しながら作業を進め、欲しいデータを短期間で得ることができました。